Publications
Find my publications here. You an also check out my Google Scholar profile.
2025
-
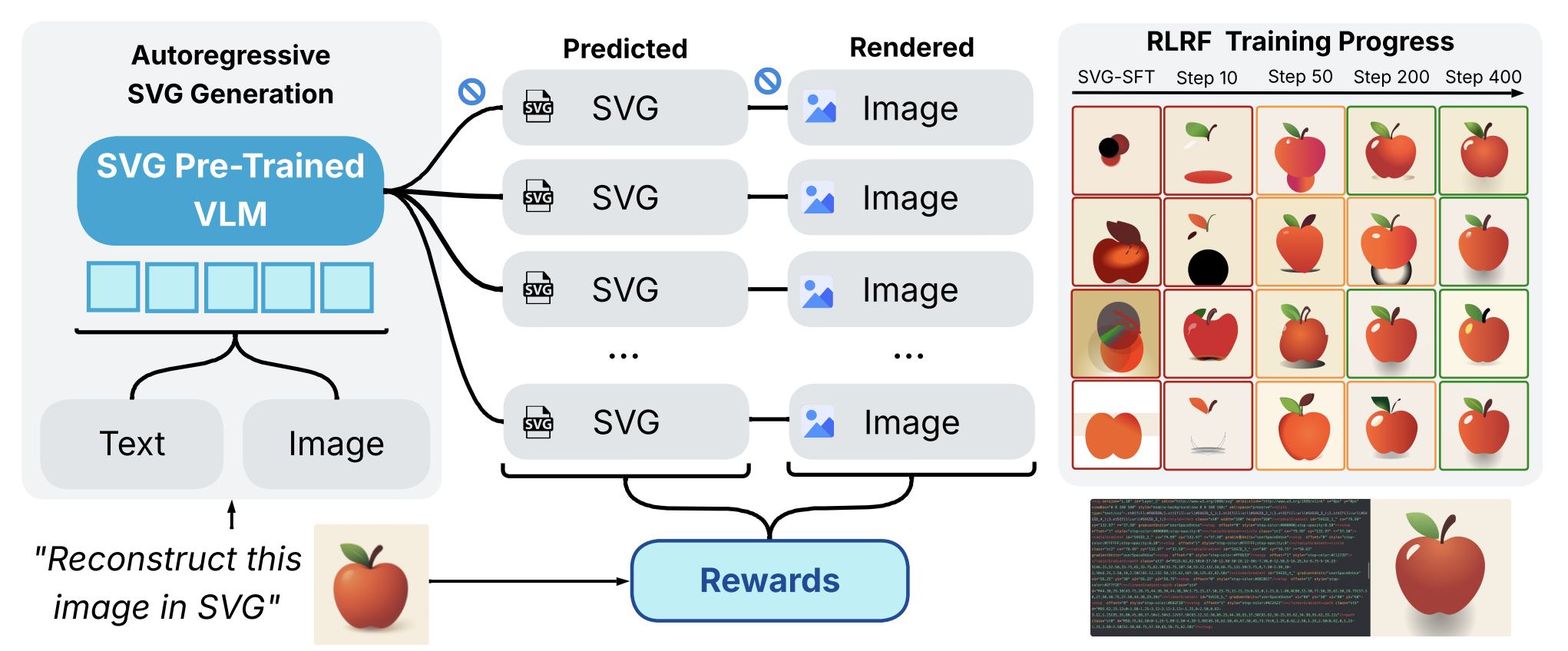 Rendering-Aware Reinforcement Learning for Vector Graphics GenerationJoan Rodriguez, Haotian Zhang, Abhay Puri, Aarash Feizi, Rishav Pramanik, Pascal Wichmann, Arnab Mondal, Mohammad Reza Samsami, Rabiul Awal, Perouz Taslakian, and 5 more authorsIn preprint, 2025
Rendering-Aware Reinforcement Learning for Vector Graphics GenerationJoan Rodriguez, Haotian Zhang, Abhay Puri, Aarash Feizi, Rishav Pramanik, Pascal Wichmann, Arnab Mondal, Mohammad Reza Samsami, Rabiul Awal, Perouz Taslakian, and 5 more authorsIn preprint, 2025Scalable Vector Graphics (SVG) offer a powerful format for representing visual designs as interpretable code. Recent advances in vision-language models (VLMs) have enabled high-quality SVG generation by framing the problem as a code generation task and leveraging large-scale pretraining. However, existing VLM approaches often struggle to produce faithful and efficient SVGs because they never observe the rendered images during training. We introduce RLRF (Reinforcement Learning from Rendering Feedback), an RL method that enhances SVG generation in autoregressive VLMs by leveraging feedback from rendered SVG outputs. Given an input image, the model generates SVG roll-outs that are rendered and compared to the original image to compute a reward. This visual fidelity feedback guides the model toward producing more accurate, efficient, and semantically coherent SVGs. RLRF significantly outperforms supervised fine-tuning, addressing common failure modes and enabling precise, high-quality SVG generation with strong structural understanding and generalization.
-
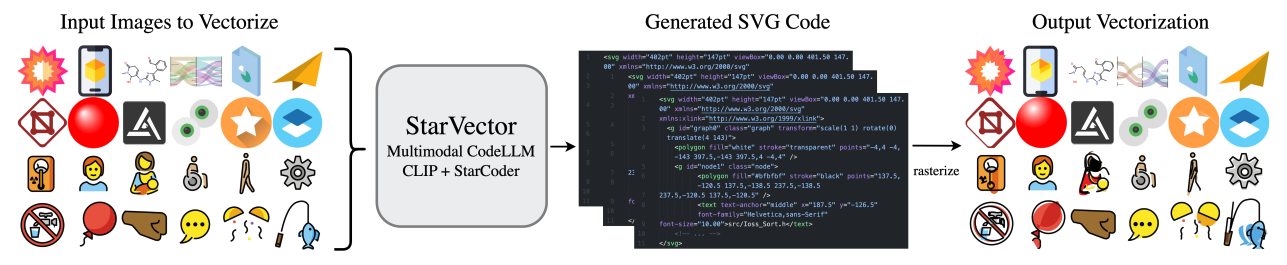 StarVector: Generating Scalable Vector Graphics Code from Images and TextJoan Rodriguez, Abhay Puri, Shubham Agarwal, Sai Rajeswar, Issam H. Laradji, Pau Rodriguez, David Vazquez, Christopher Pal, and Marco PedersoliIn CVPR 2025, 2025
StarVector: Generating Scalable Vector Graphics Code from Images and TextJoan Rodriguez, Abhay Puri, Shubham Agarwal, Sai Rajeswar, Issam H. Laradji, Pau Rodriguez, David Vazquez, Christopher Pal, and Marco PedersoliIn CVPR 2025, 2025Scalable Vector Graphics (SVGs) have become integral in modern image rendering applications due to their infinite scalability in resolution, versatile usability, and editing capabilities. SVGs are particularly popular in the fields of web development and graphic design. Existing approaches for SVG modeling using deep learning often struggle with generating complex SVGs and are restricted to simpler ones that require extensive processing and simplification. This paper introduces StarVector, a multimodal SVG generation model that effectively integrates Code Generation Large Language Models (CodeLLMs) and vision models. Our approach utilizes a CLIP image encoder to extract visual representations from pixel-based images, which are then transformed into visual tokens via an adapter module. These visual tokens are pre-pended to the SVG token embeddings, and the sequence is modeled by the StarCoder model using next-token prediction, effectively learning to align the visual and code tokens. This enables StarVector to generate unrestricted SVGs that accurately represent pixel images. To evaluate StarVector’s performance, we present SVG-Bench, a comprehensive benchmark for evaluating SVG methods across multiple datasets and relevant metrics. Within this benchmark, we introduce novel datasets including SVG-Stack, a large-scale dataset of real-world SVG examples, and use it to pre-train StarVector as a large foundation model for SVGs. Our results demonstrate significant enhancements in visual quality and complexity handling over current methods, marking a notable advancement in SVG generation technology


2024
-
 BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code TasksJoan Rodriguez, Xiangru Jian, Siba Smarak Panigrahi, Tianyu Zhang, Aarash Feizi, Abhay Puri, Akshay Kalkunte, François Savard, Ahmed Masry, Shravan Nayak, and 33 more authors2024
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code TasksJoan Rodriguez, Xiangru Jian, Siba Smarak Panigrahi, Tianyu Zhang, Aarash Feizi, Abhay Puri, Akshay Kalkunte, François Savard, Ahmed Masry, Shravan Nayak, and 33 more authors2024Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at this https URL .
-
 Too Big to Fool: Resisting Deception in Language ModelsMohammad Reza Samsami, Mats Leon Richter, Joan Rodriguez, Megh Thakkar, Sarath Chandar, and Maxime GasseIn preprint, 2024
Too Big to Fool: Resisting Deception in Language ModelsMohammad Reza Samsami, Mats Leon Richter, Joan Rodriguez, Megh Thakkar, Sarath Chandar, and Maxime GasseIn preprint, 2024Large language models must balance their weight-encoded knowledge with in-context information from prompts to generate accurate responses. This paper investigates this interplay by analyzing how models of varying capacities within the same family handle intentionally misleading in-context information. Our experiments demonstrate that larger models exhibit higher resilience to deceptive prompts, showcasing an advanced ability to interpret and integrate prompt information with their internal knowledge. Furthermore, we find that larger models outperform smaller ones in following legitimate instructions, indicating that their resilience is not due to disregarding in-context information. We also show that this phenomenon is likely not a result of memorization but stems from the models’ ability to better leverage implicit task-relevant information from the prompt alongside their internally stored knowledge.
-
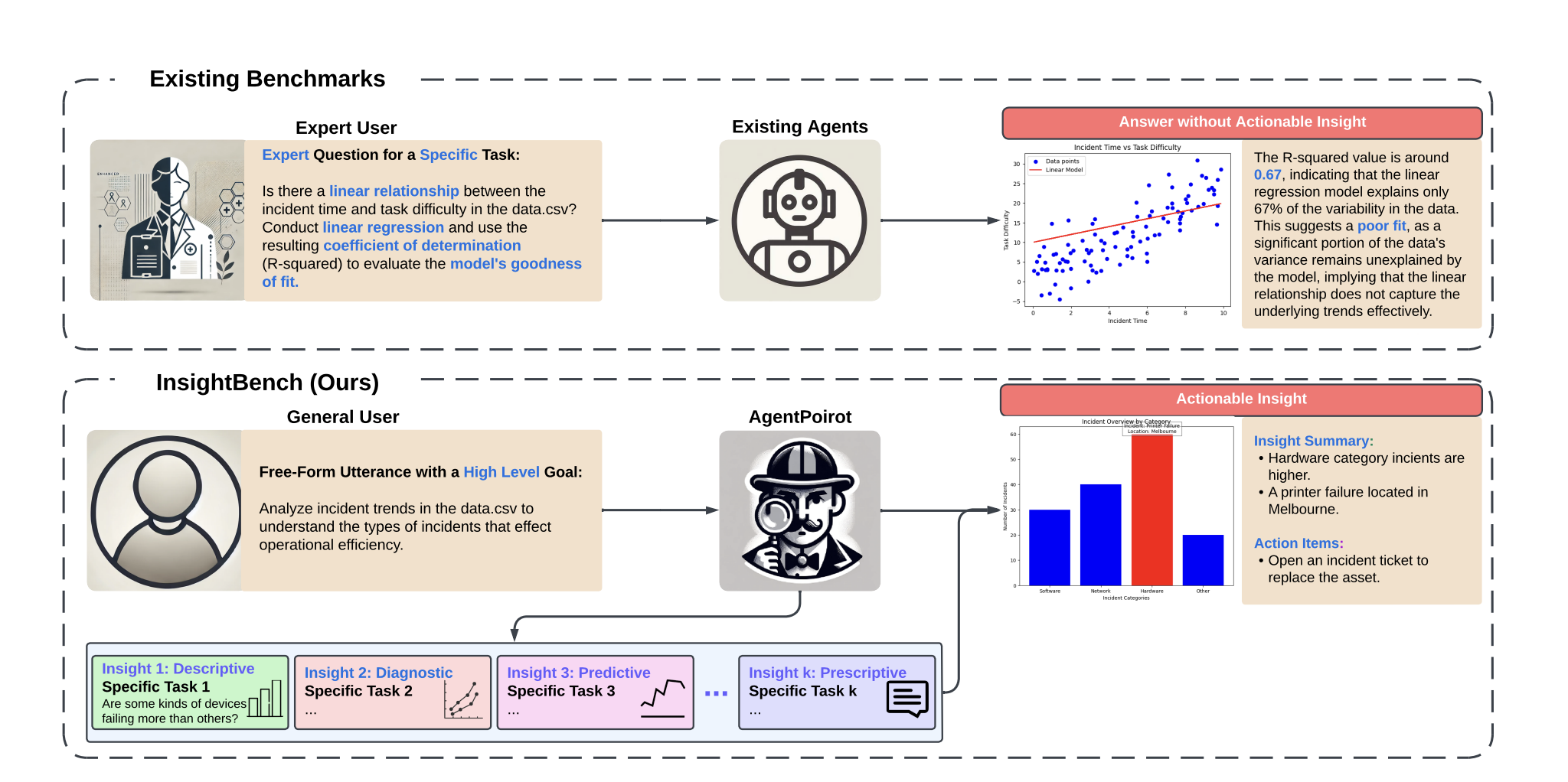 InsightBench: Evaluating Business Analytics Agents Through Multi-Step Insight GenerationGaurav Sahu, Abhay Puri, Joan Rodriguez, Amirhossein Abaskohi, Mohammad Chegini, Alexandre Drouin, Perouz Taslakian, Valentina Zantedeschi, Alexandre Lacoste, David Vazquez, and 4 more authors2024
InsightBench: Evaluating Business Analytics Agents Through Multi-Step Insight GenerationGaurav Sahu, Abhay Puri, Joan Rodriguez, Amirhossein Abaskohi, Mohammad Chegini, Alexandre Drouin, Perouz Taslakian, Valentina Zantedeschi, Alexandre Lacoste, David Vazquez, and 4 more authors2024Data analytics is essential for extracting valuable insights from data that can assist organizations in making effective decisions. We introduce InsightBench, a benchmark dataset with three key features. First, it consists of 100 datasets representing diverse business use cases such as finance and incident management, each accompanied by a carefully curated set of insights planted in the datasets. Second, unlike existing benchmarks focusing on answering single queries, InsightBench evaluates agents based on their ability to perform end-to-end data analytics, including formulating questions, interpreting answers, and generating a summary of insights and actionable steps. Third, we conducted comprehensive quality assurance to ensure that each dataset in the benchmark had clear goals and included relevant and meaningful questions and analysis. Furthermore, we implement a two-way evaluation mechanism using LLaMA-3 as an effective, open-source evaluator to assess agents’ ability to extract insights. We also propose AgentPoirot, our baseline data analysis agent capable of performing end-to-end data analytics. Our evaluation on InsightBench shows that AgentPoirot outperforms existing approaches (such as Pandas Agent) that focus on resolving single queries. We also compare the performance of open- and closed-source LLMs and various evaluation strategies. Overall, this benchmark serves as a testbed to motivate further development in comprehensive automated data analytics.
-
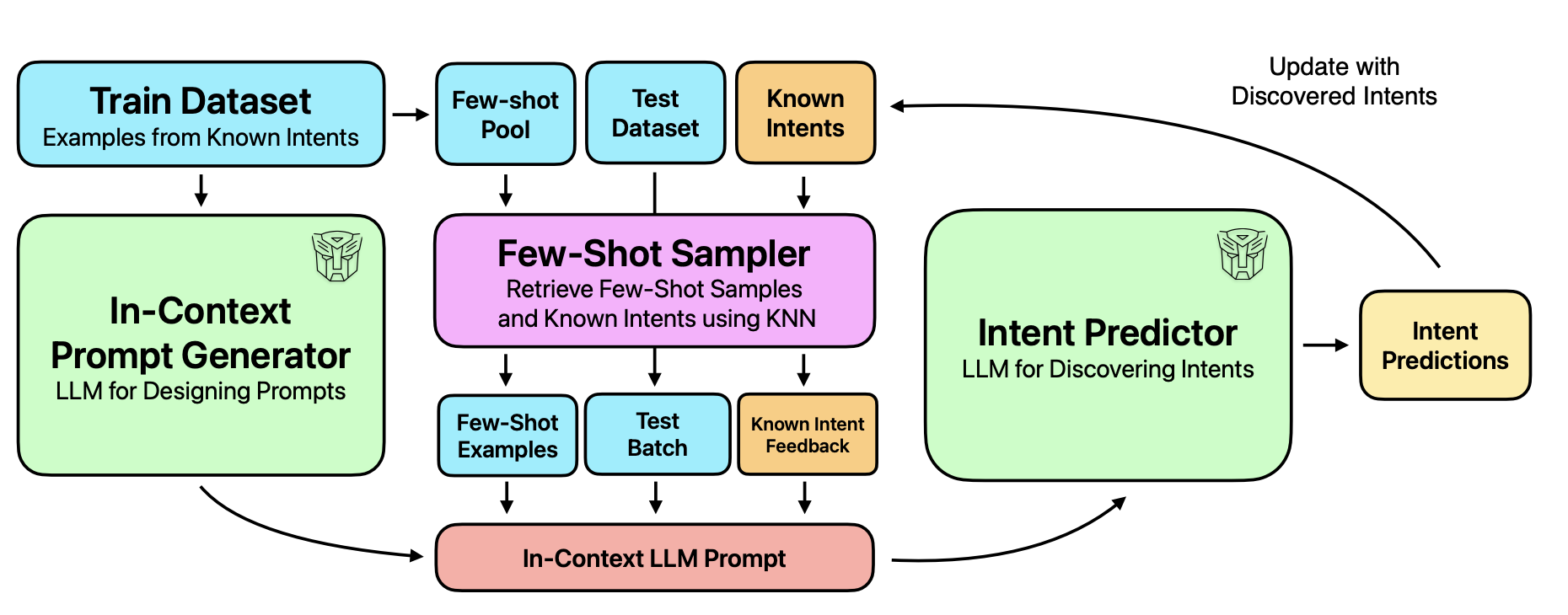 IntentGPT: Few-shot Intent Discovery with Large Language ModelsJoan Rodriguez, Nicholas Botzer, David Vazquez, Christopher Pal, Marco Pedersoli, and Issam Laradji2024
IntentGPT: Few-shot Intent Discovery with Large Language ModelsJoan Rodriguez, Nicholas Botzer, David Vazquez, Christopher Pal, Marco Pedersoli, and Issam Laradji2024In today’s digitally driven world, dialogue systems play a pivotal role in enhancing user interactions, from customer service to virtual assistants. In these dialogues, it is important to identify user’s goals automatically to resolve their needs promptly. This has necessitated the integration of models that perform Intent Detection. However, users’ intents are diverse and dynamic, making it challenging to maintain a fixed set of predefined intents. As a result, a more practical approach is to develop a model capable of identifying new intents as they emerge. We address the challenge of Intent Discovery, an area that has drawn significant attention in recent research efforts. Existing methods need to train on a substantial amount of data for correctly identifying new intents, demanding significant human effort. To overcome this, we introduce IntentGPT, a novel training-free method that effectively prompts Large Language Models (LLMs) such as GPT-4 to discover new intents with minimal labeled data. IntentGPT comprises an \textitIn-Context Prompt Generator, which generates informative prompts for In-Context Learning, an \textitIntent Predictor for classifying and discovering user intents from utterances, and a \textitSemantic Few-Shot Sampler that selects relevant few-shot examples and a set of known intents to be injected into the prompt. Our experiments show that IntentGPT outperforms previous methods that require extensive domain-specific data and fine-tuning, in popular benchmarks, including CLINC and BANKING, among others.




2023
-
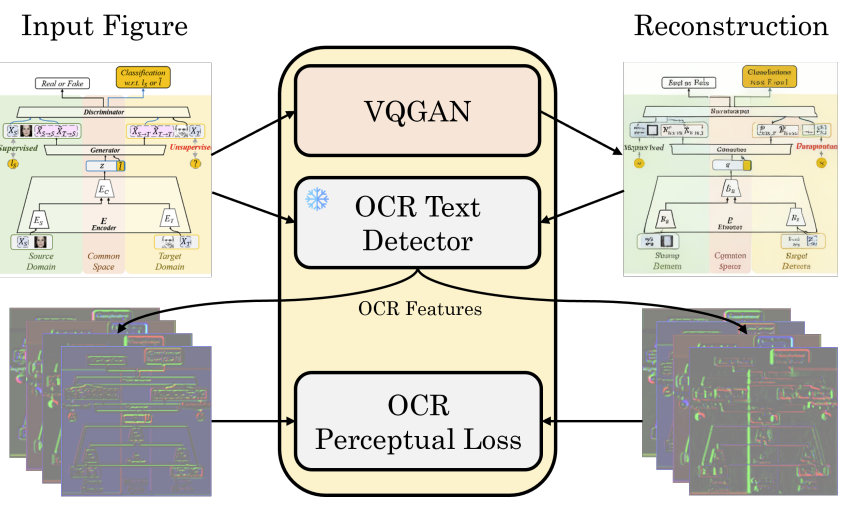 OCR-VQGAN: Taming text-within-image generationJoan Rodriguez, David Vazquez, Issam Laradji, Marco Pedersoli, and Pau RodriguezIn WACV 2023 (Oral), 2023
OCR-VQGAN: Taming text-within-image generationJoan Rodriguez, David Vazquez, Issam Laradji, Marco Pedersoli, and Pau RodriguezIn WACV 2023 (Oral), 2023Synthetic image generation has recently experienced significant improvements in domains such as natural image or art generation. However, the problem of figure and diagram generation remains unexplored. A challenging aspect of generating figures and diagrams is effectively rendering readable texts within the images. To alleviate this problem, we present OCR-VQGAN, an image encoder, and decoder that leverages OCR pre-trained features to optimize a text perceptual loss, encouraging the architecture to preserve high-fidelity text and diagram structure. To explore our approach, we introduce the Paper2Fig100k dataset, with over 100k images of figures and texts from research papers. The figures show architecture diagrams and methodologies of articles available at arXiv.org from fields like artificial intelligence and computer vision. Figures usually include text and discrete objects, e.g., boxes in a diagram, with lines and arrows that connect them. We demonstrate the effectiveness of OCR-VQGAN by conducting several experiments on the task of figure reconstruction. Additionally, we explore the qualitative and quantitative impact of weighting different perceptual metrics in the overall loss function. We release code, models, and dataset at this https URL.
-
 FigGen: Text to Scientific Figure GenerationJoan Rodriguez, David Vazquez, Issam Laradji, Marco Pedersoli, and Pau RodriguezIn ICLR 2023 (Tiny paper track), 2023
FigGen: Text to Scientific Figure GenerationJoan Rodriguez, David Vazquez, Issam Laradji, Marco Pedersoli, and Pau RodriguezIn ICLR 2023 (Tiny paper track), 2023The generative modeling landscape has experienced tremendous growth in recent years, particularly in generating natural images and art. Recent techniques have shown impressive potential in creating complex visual compositions while delivering impressive realism and quality. However, state-of-the-art methods have been focusing on the narrow domain of natural images, while other distributions remain unexplored. In this paper, we introduce the problem of text-to-figure generation, that is creating scientific figures of papers from text descriptions. We present FigGen, a diffusion-based approach for text-to-figure as well as the main challenges of the proposed task. Code and models are available at this https URL


2021
-
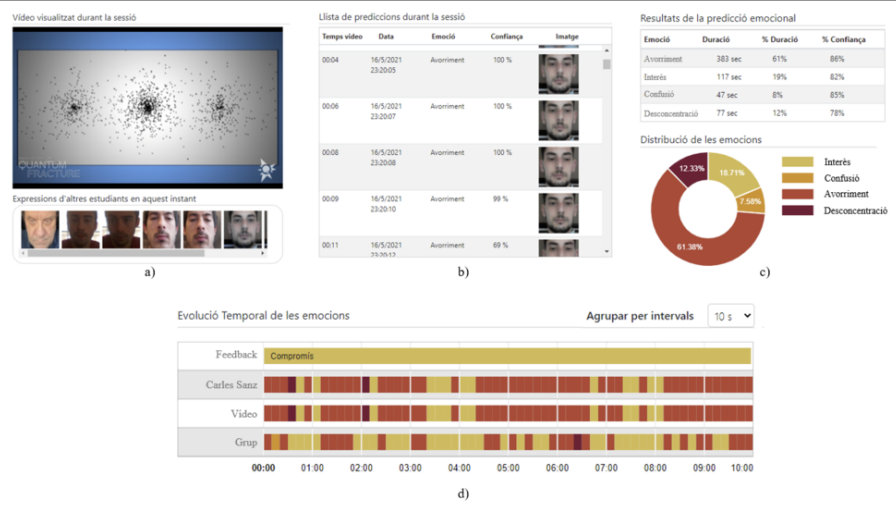 Affective State-Based Framework for e-Learning SystemsJoan Rodriguez, Joaquim Comas, and Xavier BinefaIn CCIA 2021 (Oral), 2021
Affective State-Based Framework for e-Learning SystemsJoan Rodriguez, Joaquim Comas, and Xavier BinefaIn CCIA 2021 (Oral), 2021
